Los datos como ciudadanos de primera clase
En mi trabajo uno de mis objetivos es poner orden en los datos. Los datos (especialmente los datos maestros), no son únicamente tablas para que nuestras aplicaciones funcionen con su CRUD, también son un activo muy importante del negocio y como tal no podemos evolucionar de cualquier forma. Es un gran error pensar únicamente en los datos desde el punto de vista de las aplicaciones, es necesario tener una buena política de gestión de los datos.
En la empresa hemos partido de una aplicación para e-commerce que hemos utilizado y evolucionado para guardar todos nuestros datos de negocio, y ahora están fuertemente acoplados a esa arquitectura de la aplicación. En su momento fue una elección acertada, nos ha permitido validar el modelo de negocio, evolucionarlo, experimentar y, ahora toca eliminar las limitaciones.
Para esto, estamos construyendo una API sobre la estructura original de los datos, que nos permiten acceder a ellos como a nosotros nos interesa, de una forma centralizada y desacoplada de cualquier aplicación. Además gracias a una buena separación de capas, podremos mejorar la infraestructura de los datos sin romper las aplicaciones, ya que su acceso no es directo a las tablas o ficheros sino mediante la API.
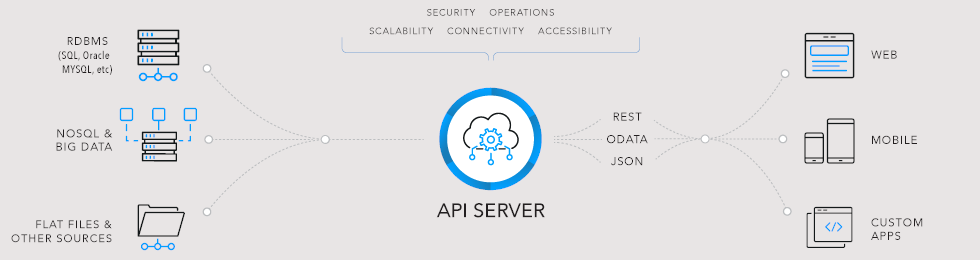
Fuente: cdata.com
Nuevo reto: integrar un ERP y gestionar nuevos datos
Estamos abordando la integración de una aplicación ERP, que lógicamente necesita su propia base de datos utilizando nuestros datos maestros y que vamos sincronizando con nuestra API. Ahora nos encontramos que en el ERP vamos a disponer de nueva información útil para nuestros análisis, así que nos podemos plantear ¿Dónde deben estar ahora los datos centralizados? ¿Divididos? ¿Disponemos de dos fuentes de datos principales? ¿Sincronizamos?
En mi opinión debemos que evitar el atajo de acoplar nuevos desarrollos sobre una aplicación, aunque es factible esto nos volverá a atar a su ciclo de vida, y realmente debería mantener su funcionalidad independiente. No volver a lidiar con los desarrollos acoplados ya que suponen añadir complejidad al sistema. Los desarrollos que sí tienen sentido ahí son los que expanden y evolucionan aquellas funcionalidades que son de su cometido.
Integrar desarrollos fuera del ámbito de las responsabilidades intrínsecas del ERP es posible, pero este no se ha diseñado para eso, aunque tenga un amplio sistema modular para ello. Debemos evitar construir sobre una base ideada para otro fin haciendo dependientes unos desarrollos de otros.
El mejor sitio para centralizar los datos: acceso mediante una API
Disponer un acceso centralizado a los datos, con una integración estándar y sobre una única aplicación de acceso, nos da la flexibilidad de abstraer por completo cómo y dónde estamos guardándolos. Las nuevas aplicaciones solo deben disponer de un conector estándar para poder utilizar toda la información disponible vía API. Además la API podrá hacer internamente consultas tan complejas como se necesiten, ya que técnicamente tiene la gran ventaja del acceso directo a la fuente de datos.
La API se erige así como nuestro MDM HUB y como única fuente de verdad. Un punto de acceso único donde gira toda la información de negocio, y donde las nuevas aplicaciones que trabajan de forma independiente encuentran la información clave en un único lugar.
El HUB trabaja en ambas direcciones, cuando una aplicación necesita modificar datos maestros lo hace por ahí (via API), y este ya se encarga de gestionar el flujo para que los cambios desciendan automáticamente sobre el resto de aplicaciones. Las aplicaciones que necesitan el dato maestro localmente estarán siempre sincronizados vía HUB. Lógicamente los datos propios de las aplicaciones que no se necesitan en otras no deben ser centralizados, permaneciendo bajo el control de su aplicación.
Los sistemas de análisis de datos siempre podrán extraer la información de forma independiente desde HUB y también desde las distintas aplicaciones para luego hacer sus procesos de análisis, independientemente de quién sea la responsabilidad del dato.
Debemos permitir evolucionar el acceso y gestión de los datos por un lado, y por otro las diferentes aplicaciones que tendrán acceso a los datos maestros centralizados. Así el sistema será menos complejo gracias a una buena división de responsabilidades de las aplicaciones. Ese desacoplamiento minimizará errores y riesgos. También evitaremos acoplamientos entre aplicaciones que nos dificulten su crecimiento, mantenimiento, etc. En algunos sitios lo llaman microservicios.