En mi “aproximación profunda” sobre la programación asíncrona, he querido estudiar la base de esa asincronía. Así que en última instancia me he visto envuelto en comprender el funcionamiento sobre la gestión de los hilos. Mi objetivo en este artículo es tratar de explicar algunos conceptos que me he encontrado sobre los hilos y cómo funcionan.
Empiezo definiendo un hilo como una secuencia de código a ejecutar. Cada hilo es seleccionado y llevado por turnos hacia el procesador iniciando así su ejecución. Esto se hace con un algoritmo planificador (scheduler) que será normalmente gestionado desde el sistema operativo (kernel).
Voy a ver algunas diferencias de los planificadores sobre cuando es delegado al sistema operativo (kernel-level), o cuando el planificador es un servicio proporcionado por el lenguaje o una librería, y que se ejecuta a nivel de usuario (user-level).
Pero un hilo también puede ser visto desde el punto de vista de un microprocesador, y como me fascina el funcionamiento de los micros he arañado un poco más para entrar a ver cómo es por dentro este asunto con el siguiente apartado.
El microprocesador y la concurrencia, y cómo es el multithreading
En un microprocesador también existe el concepto de hilos de ejecución. El micro no conoce el todo de un programa, solo se limita a ejecutar secuencias de código con un contexto que se inicializa en sus registros, básicamente para el acceso a memoria y comienzo de la ejecución.
Un micro con un núcleo sólo podrá ejecutar un único flujo de código (hilo), en cambio tenemos procesadores multi-núcleo pueden tener paralelismo real con varios flujos de código en ejecución (multi-hilo). Normalmente cada hilo tiene su propio direccionamiento, espacio de memoria, registros, etc., pero no siempre es así como veremos luego.
El sistema operativo es quién se encarga de repartir esos flujos de ejecución en los núcleos disponibles, gestionando la concurrencia de los procesos en una cola vía prioridades, estados, etc.
El multithreading de una CPU (HyperThreading en Intel, SMT en AMD, etc.) permite que un mismo núcleo pueda ejecutar 2 hilos independientes, pero con la particularidad de que esos dos hilos deben pertenecer al mismo proceso. Esto es así porque ambos hilos deben compartir el mismo contexto de ejecución como la cache, el espacio direccionamiento virtual, etc., aunque no sus registros.

Hasta aquí el fascinante mundo del microprocesador, pero luego veremos qué ventajas tiene eso de compartir el contexto entre hilos pertenecientes a un mismo proceso.
Procesos, hilos y fibras
En un ordenador pueden funcionar en paralelo muchos procesos correspondientes a unas cuantas aplicaciones y servicios del sistema operativo. Los procesos se pueden dividir en hilos de ejecución, un proceso con un único hilo es el caso más simple. La clave para la gestión de la concurrencia y la prioridad entre las aplicaciones estará en cómo y cuándo se hace el relevo entre los diferentes hilos en el procesador.
Tenemos dos estrategias básicas para estos relevos:
-
Preemptive multitasking, normalmente gestionado por el sistema operativo (kernel-level) y que en un tiempo predefinido, interrumpe al hilo para poner el siguiente sin tener en cuenta lo que está ejecutándose en ese momento.
-
Cooperative multitasking, el relevo lo lleva a cabo un planificador que está dentro del entorno de ejecución del propio proceso, vía librerías propias del lenguaje o facilitadas por el sistema operativo. Suele ser ejecutado a nivel de usuario (user-level), y donde se tiene la posibilidad de que un hilo pueda ceder su turno a otro hilo vía código. Las corrutinas son los casos más claros de esto último.
Esta estrategia cooperativa es una de las bases de la programación asíncrona. Aquí somos nosotros los que podemos controlar la concurrencia entre los hilos, ya sea directamente con sentencias deliberadas de paso de turno, o indirectamente delegando la gestión de los turnos al compilador o intérprete, que conoce bien la estructura de la aplicación.
La cooperación entre hilos nos permite optimizar mejor los recursos y prioridades, porque conocemos mejor que el sistema operativo cómo deben bloquearse y cuándo ceder el turno entre los hilos en ejecución.
Procesos (process)
Cuando lanzamos una aplicación, o un comando, o levantamos un servicio, a nivel del sistema operativo creamos un proceso (realmente a veces es un poco más complejo). El proceso se mantiene en ejecución hasta su finalización, pasando para el sistema operativo entre los estados de:
- Listo para ejecución (otros procesos tienen la prioridad)
- Suspendido (por ejemplo esperando el final de una operación de E/S)
- En ejecución (le toca el turno de procesador)
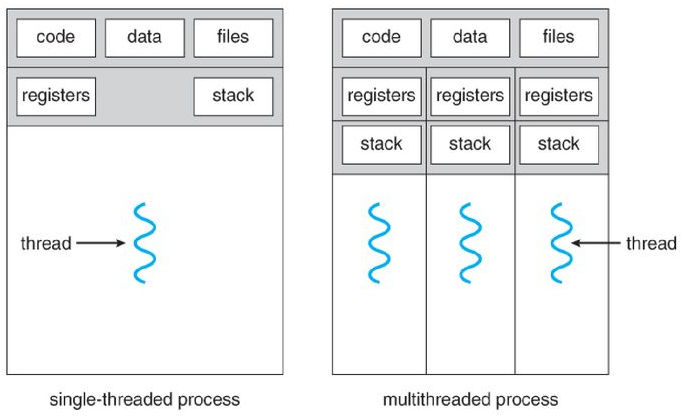
Agrupa todo el código y los recursos necesarios como los apuntadores a ficheros, sockets, variables globales, espacio de memoria asignado, etc. Un proceso puede estar compuesto por varios hilos de ejecución concurrente, y muy importante, todos los hilos comparten el direccionamiento virtual y todos los recursos globales del proceso.
A partir de aquí vamos a ver al proceso como secuencias de hilos que son gestionados por el planificador del sistema operativo, que dirige la ejecución concurrente intercambiando los hilos disponibles. El momento de cambio ocurre principalmente por que se bloquea el hilo esperando un recurso de E/S o bien se le acaba el tiempo asignado (preemptive multitasking), se sustituye por el siguiente de la cola.
CEl desalojo de un proceso por otro es relativamente costoso porque supone guardar la tabla de direccionamiento (TLB), guardar el estado del proceso, su espacio de variables y recursos, invalidación de la cache del procesador, etc., y cargar todo lo anterior del siguiente proceso. Vamos, como desenchufar y recoger todo de la mesa porque viene otro a trabajar ahí.
Un motivo por el cual un sistema puede degradarse de forma significativa es cuando muchos procesos se bloquean y son suspendidos debido al acceso a recursos (ficheros o recursos de red). Esto provoca que tengan que ser desalojados y posteriormente recuperados, teniendo que dedicar el procesador demasiado tiempo con los cambios de contexto.
Una operación de cambio de un proceso puede llegar a consumir hasta 106 ciclos de procesador y también supone un significativo gasto de memoria donde mantener todo el contexto de los procesos.
Hilos (threads)
Cuando un proceso se divide en diferentes hilos de código, todos se ejecutan de forma concurrente. Esta división tiene ventajas como que una operación bloqueante en uno de los hilos (como un acceso a un recurso) no tenga necesariamente que suspender el proceso completo.
También son especialmente útiles cuando un servicio lanza hilos (estática o dinámicamente) para atender a muchos clientes de forma independiente y concurrente para cada hilo. Estos comparten el código, sus variables y recursos globales, aunque no directamente su información local.
Otra ventaja de los hilos se da cuando el planificador desaloja un hilo por otro que también pertenece a un mismo proceso, es mucho menos costoso porque todos los hilos comparten toda la información del proceso, salvo la pila, registros y las variables locales del hilo si existieran. Un kernel moderno puede tener todo esto en cuenta y el cambio de contexto así es mucho más simple y rápido. En el ejemplo anterior de la mesa, me vale con llevarme mis cosas personales y dejar que el siguiente utilice el mismo ordenador, flexo, etc. pero abriendo su propia aplicación, el cambio es más rápido.
Vamos a diferenciar los kernel threads, user threads y fibers (fibras), estrategias para lidiar con la concurrencia y sobre todo con los costosos bloqueos de los hilos.
kernel threads
El sistema operativo puede ofrecer un servicio nativo de gestión de hilos que se ejecuta a nivel del kernel. El proceso crea y delega la gestión de la ejecución de los hilos al kernel. El funcionamiento es el que ya hemos visto para procesos. El sistema operativo puede aprovechar la ventaja de conocer qué hilos pertenecen a un mismo proceso para intercambios más eficientes de hilos, y también la posibilidad de aprovechar el multithread si está disponible.
Pero cuando el kernel interrumpe al hilo, no sabe en qué momento lo hace, se le acaba su tiempo y es desalojado. Por ejemplo cuando un hilo a punto de finalizar es desalojado y debe esperar a su próximo turno para terminar sus últimas instrucciones.
Esto es importante tenerlo en cuenta para cuando veamos el siguiente tipo de planificación basado en cooperative multitask y las ventajas que supone.
user threads
En estos casos no delegamos la gestión de los hilos directamente al sistema operativo, sino que disponemos de un planificador (runtime) en una capa por encima del kernel que decide que hilo del proceso dispone de acceso al procesador. Se denominan user threads porque ese planificador se ejecuta en el espacio de usuario (user-level).
La concurrencia de los hilos se pueden implementar de muchas formas, e incluso de forma híbrida usando los propios recursos del sistema operativo. Por ejemplo tenemos el concepto de los green threads o virtual threads, que no utiliza el sistema nativo del kernel para gestionar los hilos. En su lugar se utiliza un runtime o una máquina virtual del propio compilador / intérprete del lenguaje, tenemos por ejemplo la JVM de java.
Con este tipo de planificador el intercambio de hilos puede ser ajustado al máximo en función de lo que deba conservar como contexto entre los hilos involucrados. No es lo mismo una función invariante, una corrutina, un generador, etc. Así se permite al planificador utilizar la máxima eficiencia para desalojar el hilo anterior y alojar el siguiente. Esto significa por ejemplo que quizás no deba guardar y recuperar todos los registros del procesador para ese cambio de hilo.
Se suele utilizar la concurrencia cooperativa entre hilos, y es especialmente útil para la programación asíncrona. Piensa como los async, away, yield, etc., hacen posible esa concurrencia cooperativa anticipando cuando un hilo se bloquea o pasa el turno de ejecución a otro hilo.
Aún así las operaciones de E/S siguen suponiendo un reto, pero existen estrategias que permiten trasladar los bloqueos a otros hilos o procesos especializados a los que se delega esta ejecución, evitando el bloqueo del hilo principal que simplemente continua o es detenido de una forma más ordenada en favor de otros hilos. Podemos intuir aquí cómo pueden funcionar las Promises, Futures, ...
Para el sistema operativo los user threads son un hilo más que está ejecutando, todo lo que hace el planificador del lenguaje dentro de ese hilo cambiando flujos de código es completamente transparente para el kernel. Los sistemas operativos más modernos incluso ofrecen recursos para hacer todo esto de forma híbrida entre planificador del runtime junto con el kernel para mejorar la eficiencia y la seguridad.
fibers (fibras)
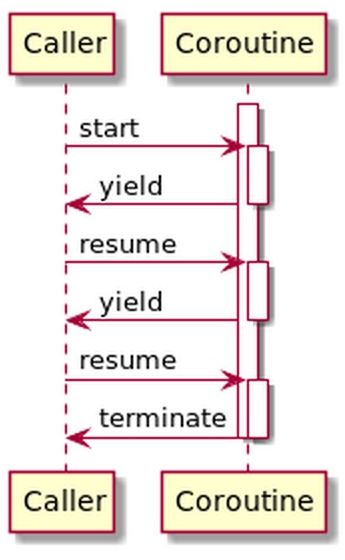
Dentro de los user threads y de la concurrencia cooperativa tenemos un tipo de hilos muy especializados donde suele emplearse el concepto de fibra (fiber). Son flujos de código que de forma cooperativa van pasándose el control entre ellos y el intercambio de hilos es notablemente más ligero a nivel de ciclos de procesador.
Son gestionados íntegramente dentro del espacio del lenguaje, creando, inicializando y lanzando las fibras necesarias. Las fibras no son una subdivisión de los hilos, más bien podemos verlos como una especialización más eficiente de hilos que se crean y que cooperan entre ellos.
Se asemejan mucho al concepto de corrutinas y son fragmentos de código que no suelen finalizar, se suspende y reanuda bajo demanda y puede ir acompañadas por una transmisión de datos, guardar estados previos o compartir datos entre ejecuciones.
Fuente: http://www.cs.us.es/~fsancho/?e=234
Con las fibras podemos ver claramente como funcionan a bajo nivel los generadores, iteradores, listas infinitas, etc.
Espero haber sido claro y preciso en las explicaciones. Pero si no ha sido así, por favor, no dudes en ponerte en contacto conmigo.