Una de las grandes ventajas de la asincronía es poder aprovechar mucho más eficientemente los recursos de la CPU. Esto es así porque los algoritmos pueden ejecutarse de forma concurrente y coordinada en diferentes hilos, permitiendo que un proceso no tenga que bloquearse necesariamente esperando el resultado de una operación que ha delegado.
Voy a centrarme en uno de los que más impacto tiene sobre el rendimiento, el bloqueo de hilos por operaciones de entrada y salida (E/S o I/O en inglés).
Con el auge de los micro-servicios, el cloud y otros recursos vía internet, el reto ya no es el acceso a disco o a la base de datos en la red local, sino el acceso desde nuestras aplicaciones a todos esos recursos aún más lentos.
En programación tradicional síncrona, cuándo el código llega a un punto en el debe realizar esta operación de E/S, el hilo que lo ejecuta se bloquea, esperando una respuesta o un timeout del recurso. Como comentaba en la gestión de hilos esto es costoso de gestionar a nivel de kernel, ya que ha de desalojar el hilo de código y alojar el siguiente.
Con la programación asíncrona se nos abre nuevas posibilidades para aprovechar mejor los recursos como atender más peticiones, lanzar otras peticiones en paralelo, refrescar información en pantalla, etc.
One-thread-per-request (un hilo por petición)
Por ejemplo, en el desarrollo de un servicio que atienden a un número concurrente de clientes, la mayoría de los lenguajes suelen emplear este modelo para la gestión de recursos, donde lanzamos un nuevo hilo para cada petición a nuestra aplicación.
Funciona bien cuando tenemos poca carga o esta es muy estable, pero su rendimiento cae rápidamente en entornos de mucha carga, por el exceso de trabajo de la gestión de hilos y el consumo de memoria que supone, ya que muchos de esos hilos se encuentran bloqueados.
Seguro que habéis visto alguna vez el error 503 Server busy, y es que el servicio ya no puede atender más peticiones hasta que no se desatasque.
Dos modelos para la implementación de la asincronía
Vamos a ver dos modelos para implementar la programación asíncrona y que aprovecha las ventajas de los lightweight threads, donde el intercambio de hilos es mucho más rápido y más liviano en el microprocesador.
Estos modelos gestionan sus bloqueos dentro del espacio de usuario (user-level) antes que ocurran y sean llevados al kernel.
1. Thread based
También llamados work-stealing permiten que los hilos puedan delegar las operaciones de E/S a un grupo de hilos especializados (worker-threads), quienes completan la tarea de forma independiente. Al terminar suelen invocar a una función callback establecida por el hilo invocador.
Cuando el hilo delega esa operación este puede continuar su ejecución de forma asíncrona sin que el proceso se bloquee, permitiendo un control de cómo ha de comportarse después de la llamada hasta recibir la respuesta, como seguir haciendo más operaciones, atender nuevas peticiones o ceder el turno al siguiente hilo del proceso.
Los hilos delegados que ejecutan las acciones de E/S terminan finalmente bloqueados, pero la diferencia es que el bloqueo solo se produce en ese grupo de hilos y no en los hilos solicitantes. El rendimiento del proceso aumenta de forma importante, pues es capaz de continuar su ejecución en lugar de estar detenido en espera de resultados.
El reto lo tenemos ahora en cómo retornar el control al hilo invocador desde el hilo delegado. Hay varias respuestas posibles: el resultado esperado, un error desde la operación remota, o bien un timeout porque que el recurso no ha respondido.
El método habitual son las conocidas funciones de callback donde el hilo finaliza devolviendo el control al primer hilo junto con un posible resultado como parámetro. Algunos lenguajes utilizan para construir este escenario implementaciones como Promises o Futures. También es posible registrar diferentes callbacks en función de si es una respuesta correcta o un error, por ejemplo onSuccess o onError, etc.
Problemillas con este esquema
Para este modelo suele planificarse una configuración previa de cómo inicializar el pool de worker-threads. En una carga estable y conocida es sencillo, pero para una carga indeterminada puede suponer o un desperdicio de recursos (si inicializamos de más) o problemas de recursos (si inicializamos de menos).
Por otro lado, el bloqueo de hilos sigue produciéndose dentro del proceso, aunque sean en otro grupo de hilos, teniendo que gestionarse aún ese esquema de bloqueos BIO (Blocked I/O) Para un gran volumen puede suponer un más que significativo uso de recursos.
Por ejemplo, en los famosos comparadores de servicios, digamos seguros, cada petición lanza a su vez 20 peticiones a diferentes compañías externas para recoger información para comparar. Una petición lanzaría 21 hilos, 1000 peticiones en un intervalo de tiempo serían 21.000 hilos. Se puede ver aquí el drama de la gestión de esta cantidad de hilos, en muchos casos bloqueados esperando respuesta.
Una forma de crecer en recursos es ampliar horizontalmente los servidores repartiendo esas 1.000 peticiones. Pero tenemos otra opción mucho más eficiente, NIO (Non-blocking I/O), Event based, o Reactive programming.
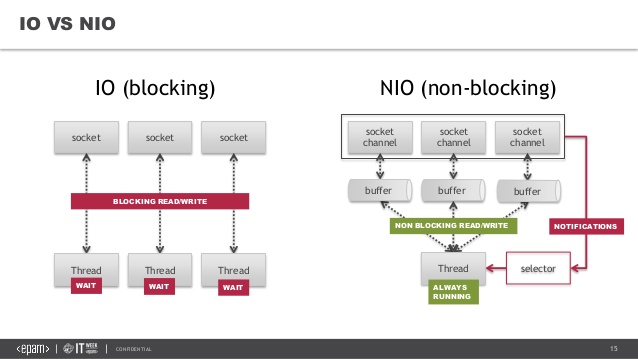
El objetivo con non-blocking I/O es evitar el crecimiento de una gran cantidad de hilos bloqueados.
2. Event based
En este modelo las operaciones de E/S se van a tratar como eventos dentro de la aplicación. La aplicación que necesita lanzar esta operación ya no necesitará crear un grupo de hilos separados para esto y su consiguiente gestión.
El sistema operativo suele ofrecer servicios para que las aplicaciones deleguen de forma asíncrona sus operaciones de E/S. Por ejemplo, en el caso de derivados de unix y según la distribución tenemos por ejemplo epoll. Estos toman la operación junto con un callback, y cuando obtiene el resultado interrumpe al hilo invocador y este último recupera la respuesta para continuar.
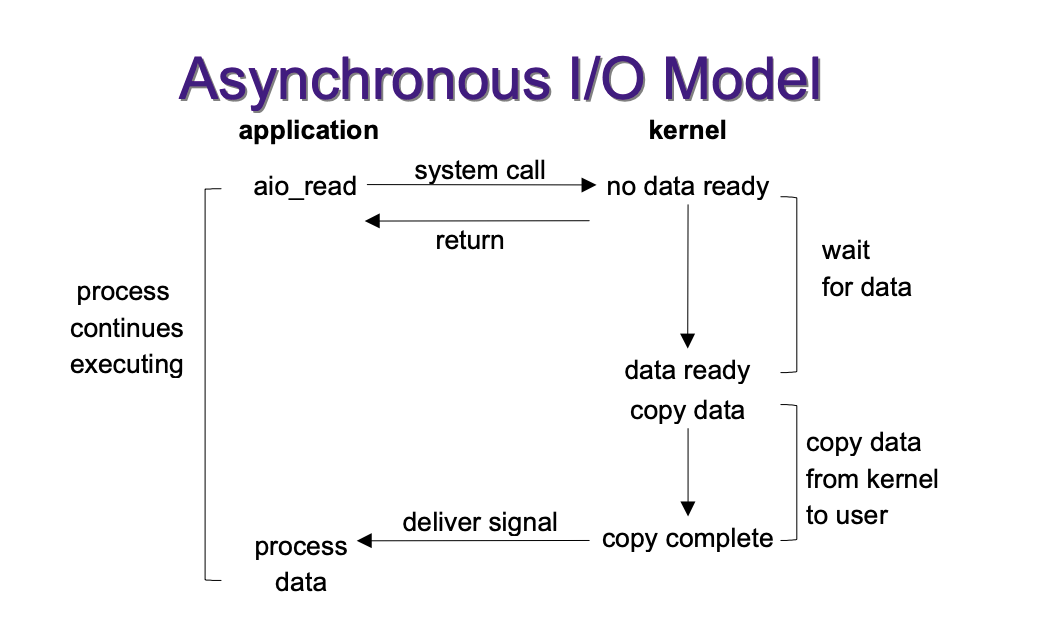
El hilo que registra esta operación no se bloquea y puede continuar su proceso. El sistema operativo puede ser mucho más eficiente que si se implementa esto a nivel de aplicaciones. Las aplicaciones por tanto no desperdician recursos para lidiar con todo esto, y tienen así la posibilidad de trabajar con una mayor carga con un código mucho más simple.
Nodejs utiliza este modelo basado en eventos en su implementación event loop. Utiliza un hilo único para gestionar una cola de peticiones e internamente gestiona la E/S utilizando los servicios de epoll del kernel, aunque hay otros como kqueue.
En esta ocasión no he querido profundizar mucho más en el artículo, porque para lo que buscaba conocer me pareció suficiente. Espero que sea útil. Y lo dicho, si hay errores o es confuso agradezco que me contactéis.